MySQL Performance Tuning, Teil 1: Tabellenlayout vernünftig planen
In den letzten Wochen und Monaten sind uns einige Projekte untergekommen, die unter abenteuerlichen Performance-Problemen aufgrund „zu großer Datenmengen“ in der MySQL-Datenbank litten. Wenn man die Tabellen richtig plant und konfiguriert, dann hat man mit MySQL aber wirklich seltenst Probleme mit der Geschwindigkeit. In einer mehrteiligen Serie von Blog-Artikeln möchten wir einige Schritte aufzeigen, wie man solche Probleme vermeiden bzw. beheben kann.
1. Tabellenlayout vernünftig planen
Bereits beim ersten Anlegen von Tabellen kann man vieles richtig machen. Der Entwickler muss abschätzen, wie sich die Datenmengen in der Zukunft entwickeln werden. Sind einzelne Tabellen dabei, die absehbar mehrere Millionen Datensätze pro Monat entwickeln, dann ist es wichtig, einen Kompromiss aus Normalisierung und Redundanz zu finden. Redundanz kann in einigen Situationen hilfreicher sein, als eine strikt normalisierte Datenhaltung.
Wichtig ist insbesondere, dass man die korrekte Storage-Engine verwendet. INNODB ist toll, wenn man Transaktionen verwenden würde. Sehr oft werden die dann später aber gar nicht gebraucht. MyISAM geht da etwas hemdsärmeliger heran, spart sich dadurch aber einiges an Overhead, was signifikante Geschwindigkeitsvorteile bei Abfragen bedeutet.
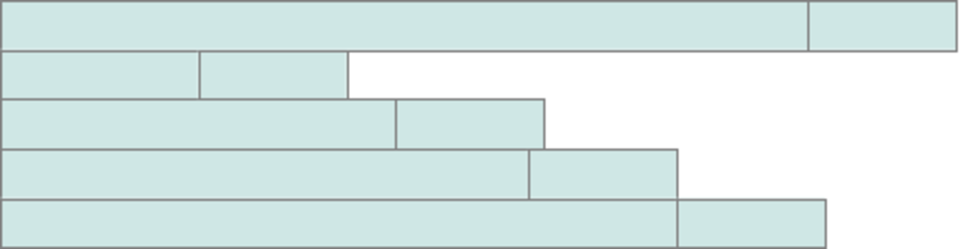
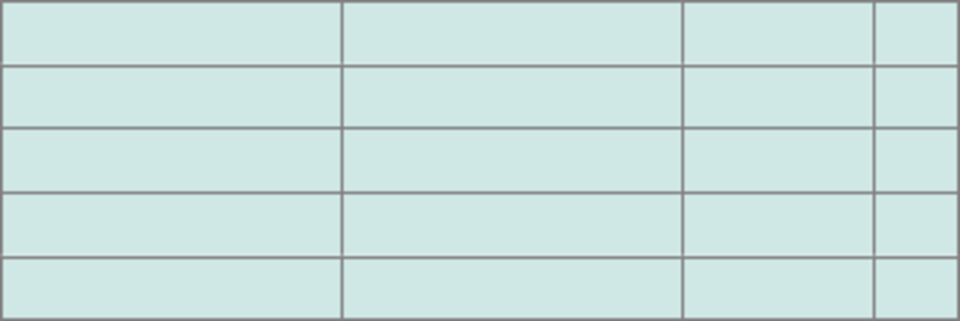
Auch erheblich wirkt sich der Unterschied zwischen Tabellen dynamischer und statischer Zeilenlänge aus. Verwendet man ausschließlich Felder mit fest definierter Länge (also keine TEXT, BLOB oder VARCHAR-Datentypen), kann MySQL einen wesentlich flotteren Algorithmus beim Suchen von Tabellenzeilen verwenden, als wenn die Zeilen unterschiedliche Länge haben. Lange Textfelder sollte man also entweder vermeiden, oder über Schlüssel fester Länge (BIGINT) in andere Tabellen oder gar Dateien auslagern. Ferner hatte ich in den letzten 10 Jahren noch nie den Fall, dass BLOB ein sinnvoller Datentyp in einer Datenbank gewesen wäre. Dateien werden im Filesystem des Servers performanter gespeichert.
Dynamisches Tabellenlayout
Statisches Tabellenlayout
Viele Entwickler vergessen nach Abschluss der Entwicklungsphase (mit wenigen Datensätzen) auch das setzen von vernünftigen Indexen. Werden SELECT-Abfragen mit WHERE oder HAVING verwendet, muss auf diese Spalten ein passender Index gesetzt sein. Wer implizite oder explizite JOINs verwendet, um weitere Tabellen in die Abfrage mit einfließen zu lassen, MUSS diese Spalten indexieren. Der dadurch zusätzlich benötigte Speicher auf der Platte ist wesentlich günstiger als die CPU-Zeit, wenn für jede Zeile einer 10-Millionen-Datenbank erst der Wert aus der Tabelle gelesen werden muss.
Ob die angelegten Indexe für die konkreten SQL-Abfragen der Anwendung tatsächlich nützlich sind bzw. angewendet werden, bekommt man mit dem EXPLAIN-Statement heraus:
EXPLAIN SELECT * FROM `testtable` WHERE c =1

Die Spalte „possible_keys“ zeigt für alle in die Abfrage einbezogenen Spalten, ob ein Index vorhanden ist. Die Spalte „key“ zeigt, ob ein Index verwendet wurde, und wenn ja, welcher. Es kann sein, dass mehrere Indexe auf einer Spalte liegen, es wird aber immer nur 1 Index verwendet, und zwar der, der nach Meinung des SQL-Servers der am besten passende ist. Steht unter „Key“ NULL, dann muss entweder die Abfrage angepasst werden, oder die gesetzten Indexe müssen angepasst bzw. ergänzt werden.